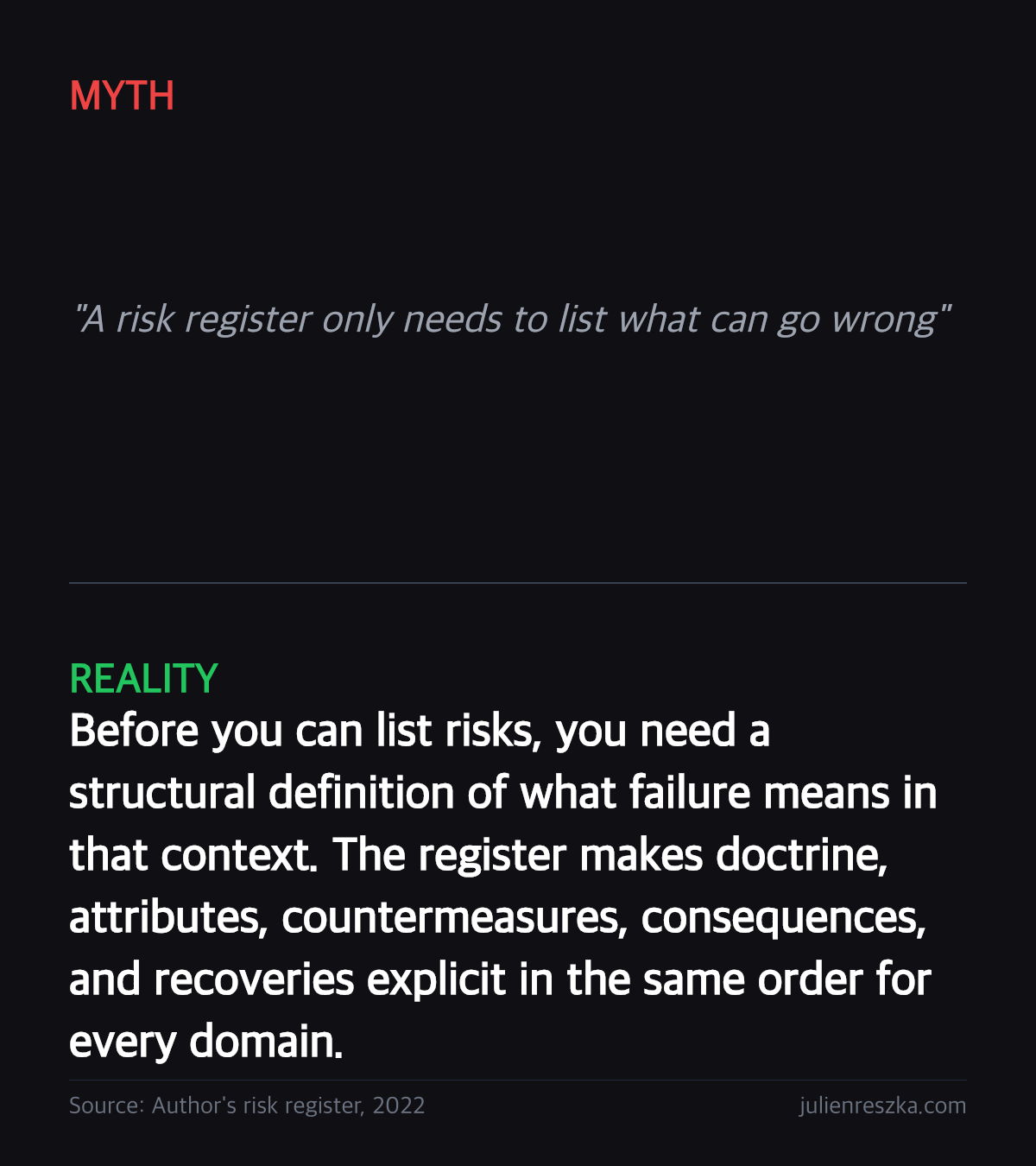
Most risk frameworks begin too late. They ask what can go wrong before defining what wrong even means in the context they are analysing.
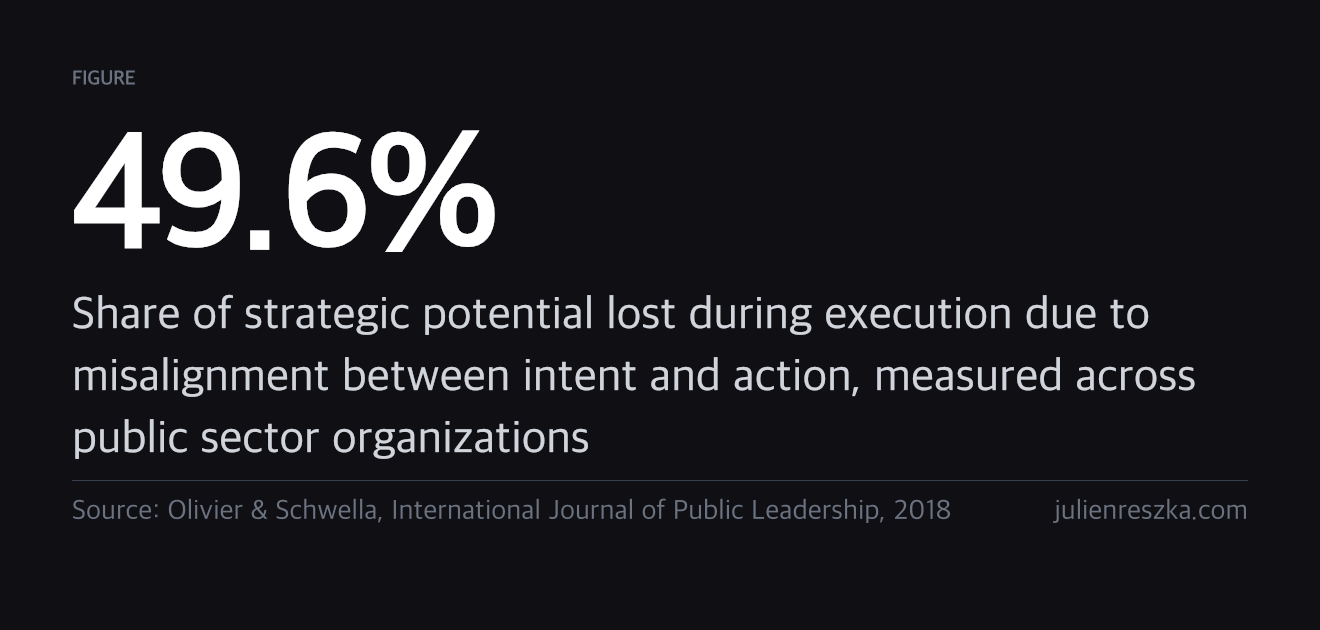
This is not a new observation. FMEA was standardized by the US military in 1949 and remains the dominant structured failure framework. It asks: what can fail, how severe, how likely. But it starts at the failure mode, not the doctrine upstream of it. That upstream layer, who has authority to define what the right belief even is for a given role, is a governance problem, not a data problem. Williams (2017, PMJ) found the same gap in practice: risk registers list risks in isolation and fail to capture causal chains. Recovery plans treat symptoms without touching the doctrine that produced them. Olivier and Schwella (2018) measured that organizations lose 49.6% of strategic potential in the gap between intent and execution, not because the strategy was wrong, but because no one named the drift.
That omission matters because a hospital, a court, a sales department, and an engineering workshop do not fail in the same content. But they do fail in the same structure. A false doctrine produces the wrong attribute in the deliverable, the wrong attribute generates risk, the risk causes consequences, and recovery has to be specified at both the risk and consequence layer.

In this register, every row uses the same anatomy:
- environment and role
- bad quality and good quality
- false doctrine and true doctrine
- actions and deliverable
- wrong attribute and right attribute
- active and passive countermeasures
- external and internal risks
- external and internal consequences
- recovery paths for each risk and consequence
The important column is false_doctrine. That is the alignment failure. In a doctor's office it may be charlatanism. In regulation it may be cronyism. In an engineering workshop it may be absurdism. The doctrine changes by sphere, but the structural path from misalignment to damage does not. The names themselves are imperfect and can be disputed. Take them as starting points for thinking, not as verdicts. The value is in the structure, not in whether charlatanism is the exact right word for a given failure mode.
That structural focus is also what makes this a generative framework rather than a descriptive one. A descriptive register catalogues the domains it has already seen; it is a lookup table. This structure is a grammar. Take a context that appears nowhere in the example dataset: a maritime port authority, a hospice care team, a satellite launch crew. The structure still applies: there is a role, a deliverable, an attribute that can drift, a doctrine behind the drift, countermeasures, consequences, and recovery paths. You do not retrieve those entries from the dataset; you derive them from the anatomy. The columns constrain what a valid entry looks like, and that constraint is what makes the output meaningful even for domains no one has catalogued yet.
That property has a direct implication for AI. A model fine-tuned on this structure would be unusually good at two questions that current systems handle poorly: what is the upstream cause of this failure, and what is the appropriate recovery given this consequence. Those are not retrieval questions. They require reasoning along the causal chain from doctrine to attribute to risk to consequence to recovery. The register makes that chain explicit in every row, which means the training signal is not just labelled examples but labelled reasoning paths. That is directly useful for AI systems that need to diagnose and correct their own behaviour, rather than merely pattern-match against past errors.
The useful move is to instrument the gap between the wrong and right attribute for each deliverable you care about. Once that gap is explicit, the countermeasures, risks, and recovery plans stop being abstract policy language and become design decisions.
The example dataset linked here was handcrafted over two years to see how far the framework could go. Thirty spheres, five roles each, every column filled. The answer is: pretty far. The structure held across domains that share nothing in surface content (from military logistics to spiritual communities to corporate legal) because the anatomy underneath them is the same.
If you want to use this approach, start with one context you actually own:
- Name the role.
- Name the deliverable.
- Define the wrong and right attribute.
- Write the false doctrine that causes the wrong one.
- Add one active and one passive countermeasure.
- Write the recovery path before the failure happens.
If you cannot name the false doctrine in your domain, you do not yet know what alignment failure looks like there.
Discussion
I like the structure but I am skeptical that you can pin down a false doctrine for every domain. In engineering, sure. But in something like sales or marketing the failure modes feel more situational than doctrinal. Is charlatanism really the right frame for a salesperson who oversells?
The names are deliberately imperfect - they are a starting point, not a verdict. For sales the false doctrine might be closer to sophism: the belief that persuasion is the goal rather than fit. The exact word matters less than the practice of naming it. Once you write down the doctrine your domain runs on, you can see when it drifts. That is the point of the column.
Do you have a filled-out version of this register somewhere? The anatomy makes sense in theory but I would like to see what it actually looks like applied to a real domain.
Yes. I put together an example covering 30 spheres, from hospitals to engineering workshops to financial advisors: register-example.csv. Each row is a full anatomy from sphere and role through to recovery paths.