
In August 2021, I am running diffusion models on my own hardware and watching them generate images that would have required a professional photographer or illustrator three years ago. The examples linked below are not stock photos or CGI renders. They are outputs from a model that received a text prompt and produced an image by iteratively denoising random noise until something coherent emerged.
The mechanism is different from GANs. Instead of a generator fighting a discriminator, diffusion models learn a single function: given a slightly noisy version of a real image, predict what the noise is. Run that prediction in reverse, starting from pure noise, and you get an image. The key insight is that this process is stable to train and easy to condition on text, which GANs were not.
What GANs failed at, diffusion models fix:
- mode collapse: GANs learned to produce outputs that fooled the discriminator rather than covering the full distribution of real images
- training instability: GANs required careful hyperparameter tuning to converge at all
- text conditioning: steering a GAN toward a specific prompt was architecturally awkward
The practical consequence is that the quality ceiling has moved. These are outputs from a single afternoon of running the model.



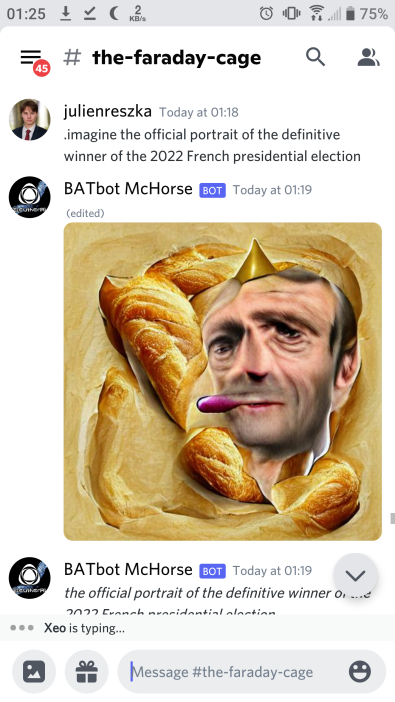
On August 9th I asked a Discord bot to generate the official portrait of the definitive winner of the 2022 French presidential election. It produced Macron's face embedded in a baguette, wearing a gold crown. The image is absurd, but the prompt was understood. The model made a political prediction, pulled Macron's face from its training data, and rendered a portrait that is surreal but recognizable. That combination, world knowledge plus image generation plus prompt following, did not exist two years ago.
Video is the obvious next step and the timeline is shorter than it looks. A video is a sequence of image frames. The same denoising process applies in the time dimension as well as the spatial dimensions. Both clips below were generated in 2021. The quality is low and the duration is short, but the structure of the problem is solved. What remains is compute and scale.
Compute costs fall on a predictable curve. The images that require hours on a high-end GPU in 2021 will require seconds on a consumer device in 2025. Video will follow the same curve with a two to three year lag. By 2024 or 2025, generating a ten-second video clip from a text description will be as accessible as generating an image is today.
The implication that gets the least attention is not about creativity or art or jobs. It is about evidence. When any image or video can be generated from a text description, a video of an event no longer proves the event happened. The tools for generating synthetic media are already ahead of the tools for detecting it, and that gap will not close quickly.

Discussion
The video examples are what got me. Images I could already explain away as photoshop. The corona video is clearly low quality but the fact that it exists as a generated output at all in 2021 is the thing I cannot dismiss.
Yes. The quality argument misses the point. Three years ago GANs could not produce coherent faces. Two years ago they could. One year ago they were photorealistic. The video is at the clearly wrong but structurally solved stage that images were at in 2019.
The evidence point at the end is the one that concerns me most. We have spent decades teaching people to trust their eyes. We have maybe two years before that trust is completely unwarranted.
Counterpoint: detection models are also advancing. By the time video generation is consumer-grade, detection should be too. The asymmetry you describe is real now but probably not permanent.
Detection has been losing the arms race against generation since deepfakes in 2018. There is a structural reason: generating a convincing output is one optimization problem, detecting all possible generation methods is a different and harder one.