You pasted the file. The agent read it. Half the context window is gone. You got three fixes.
Here is what works instead.
Write an audit script before you ask an agent to fix anything. The script scans the source, classifies each problem by type, scores it by severity, and emits one CSV line per unique issue. Then you hand the agent the CSV, not the file.
Two reasons CSV is the right format:
- CSV is the most over-represented tabular format in LLM training data. The model reads it without a schema explanation.
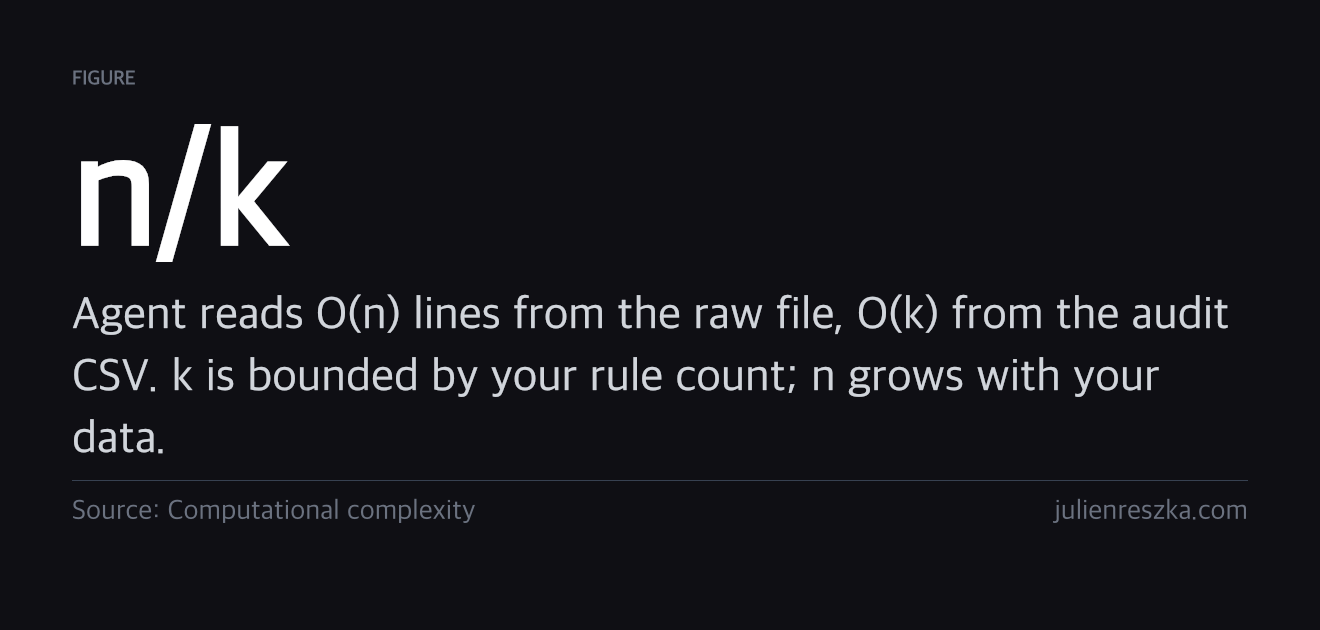
- One flagged CSV row replaces 500 lines of raw source content.
Six rules for the audit script:
- Classify, not just flag.
field:description rule:max-length offset:142is fixable. "Something is wrong" is not. - Score by severity. Group violations so the agent fixes a whole class in one pass.
- Deduplicate. One line per unique issue, not one line per row that inherits it.
- Include a snippet. Four words of context is enough to write a replacement.
- Use emojis for severity.
🔴critical,🟡warning,✅passing. One token, full meaning, still scannable by a human. - Normalize edge cases first. Batch fixing only works when violations look alike. Ask the agent to rewrite outliers into standard form before it starts fixing them.
The loop becomes: run script, read output, fix one severity class, rerun. No raw file. No bloated context. Just the issue list.
One reason to let the agent write the audit script: it already has a vocabulary for naming violations. When it writes the rule names and column headers, the output CSV uses the same terms it will later read. No translation step between detection and fix.
One useful pattern is to have the script produce two outputs: a compact CSV with one row per unique violation, and a second CSV that includes the surrounding lines for each offending value. The compact version drives the fix. The context version lets the agent verify that violations are similar enough to batch before committing to a single pass.
This is the same loop as test-driven development. In TDD you write a failing test first, then write code until the test passes, then rerun. Here you generate a failing audit report first, then fix issues until the report is clean, then rerun. The audit script is the test suite for your data. The difference is that you did not have to write the tests yourself.
This is what compilers have always done. A compiler does not paste your source code back and say "something is wrong here." It gives you a path, a line number, and a rule name. The audit script is the compiler for your data.
Try it on any structured file. A thousand-line source with a dozen real issues will produce a hundred flagged rows without deduplication. Collapse to unique issues, add severity scores, and you hand the agent a ten-line brief instead of a wall of text.
Anything you maintain in a structured file can be audited this way: product descriptions, design tokens, policy-checked content. Ask the agent to write the audit script, run it, read the output, and fix one severity class at a time. It knows regex better than you do.
There is a side benefit: you get observability for free. Open the CSV after each pass and watch the row count drop. No dashboard, no logging infrastructure. The shrinking file is the progress indicator.

Discussion
We do a lot of catalog cleanup work and the visibility thing resonates. Usually you finish a batch fix and have no idea if you made a dent or not until someone checks manually. If the script reruns and outputs fewer rows, you know immediately. That alone would have saved us a lot of back-and-forth.
Yes, and I did not realize how bad the problem was until I watched the agent burn through 80% of its context window reading a config file it was not going to touch. Wrote a 30-line audit script, handed it the output, and the same task finished in one pass. The script took longer to write than the fix took to run.
Pushback: writing the audit script is itself work. If the file is small and the task is one-off, you are adding engineering overhead to avoid a problem that costs you ten seconds. The ROI only makes sense if you are running the same audit repeatedly.
Fair for one-off tasks on small files. But the audit script also gives you a repeatable check you can add to CI. The first run pays for itself if the file has more than a handful of violations. The second run is free.
The deduplication point is underrated. I ran a naive linter over a schema with 400 rows sharing a common parent rule violation. Got 400 lines of identical output. Collapsed to unique issues and got 6 lines. The agent fixed all six in one shot.
Counterpoint: modern agents can be told to summarize findings before fixing them, which achieves the same compression without you writing a separate script. The audit script approach adds a hard dependency on a tool you have to maintain.
Telling the agent to summarize first still requires the agent to read the full file to produce the summary. You're spending context either way. The audit script spends no agent context at all on the scan phase because it runs outside the model entirely. That's the asymmetry.